Alignment Syllabus Wars Expose Divisions in AI Safety's Canon
New alignment reading lists and literature surveys are reshaping the field's self-definition, while battles over which papers make the cut expose deeper fractures in AI safety research.
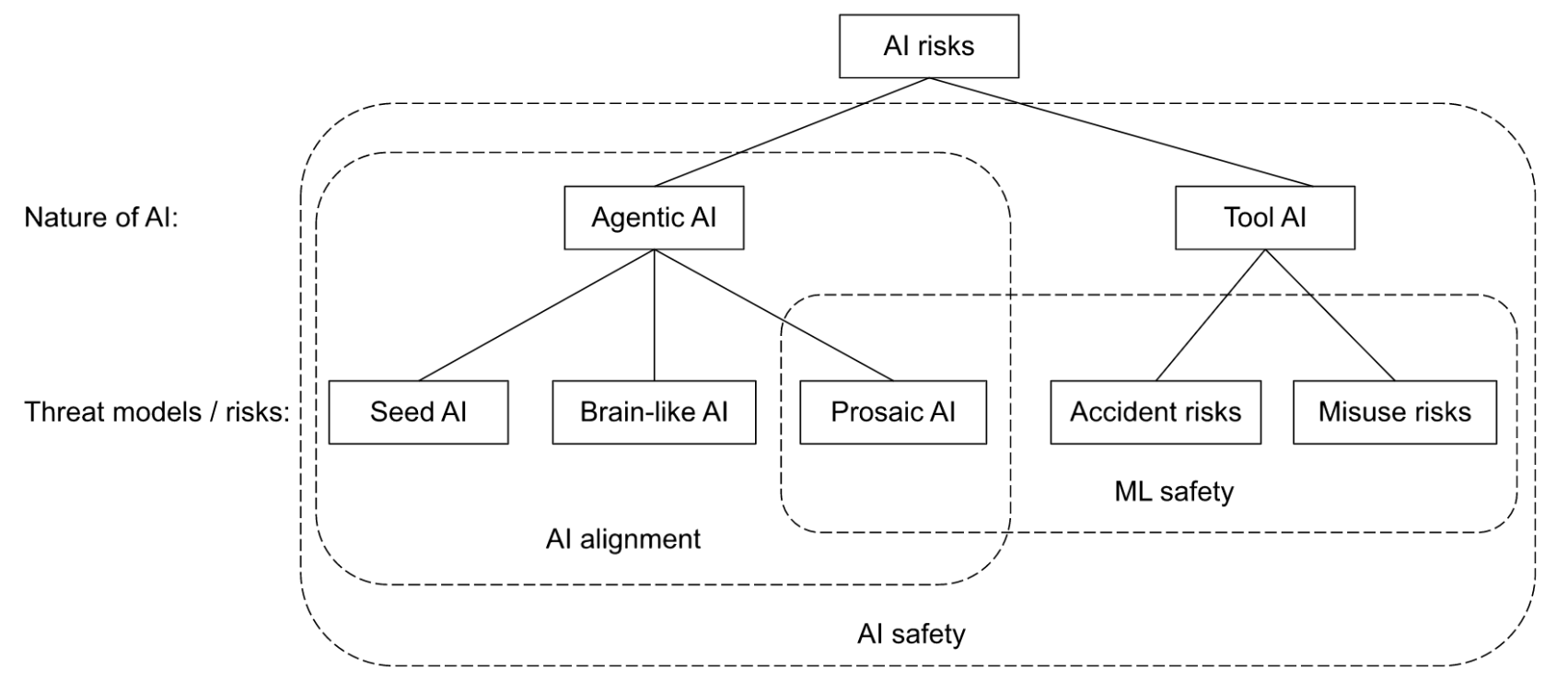 alignmentforum.org
alignmentforum.org
When a group of PhD students at the University of Toronto published a sixty-three-page alignment syllabus in March, the document's appendix contained a single table that caught more attention than the entire reading list itself. The table catalogued, across fourteen major alignment surveys and reading lists published since 2022, which papers appeared in at least half of them. The overlap was smaller than anyone expected: out of nearly four hundred unique papers cited across the fourteen lists, only eleven appeared in seven or more. The alignment field, it turned out, could not agree on what alignment even required reading. That table has been circulating in Signal groups and lab Slack channels for six weeks now, and no one I spoke to could name a single alignment researcher who did not have an opinion about what the list got wrong.
The Toronto syllabus was not an outlier. Over the past eighteen months, the number of published alignment reading lists, annotated bibliographies, and structured literature reviews has accelerated sharply. OpenAI's new Safety Fellowship, announced in April, ships with a curated bibliography of forty-seven papers that fellows are expected to have read before their first week. Anthropic's Fellows Program 2026 includes a pre-arrival reading packet that the lab describes internally as a 'minimum viable canon.' The Alignment Research Center published an updated version of its 'prerequisites document' in January, adding three new sections on control evaluations and scalable oversight. A document that began life in 2023 as a shared Google Doc among a dozen researchers has become, in 2026, something closer to an admissions exam.
The proliferation of these lists is not simply a matter of field-building or pedagogical convenience, though it is partly those things. Reading lists function as boundary objects in a research community that is still negotiating its own intellectual borders. They signal which subfields matter, which methods are legitimate, and whose work counts as foundational. When the lists diverge, they expose disagreements that the field's polite conference panels tend to smooth over. The Toronto table made those disagreements visible. One striking finding: mechanistic interpretability papers appeared at roughly double the rate in lists produced by researchers affiliated with Anthropic compared with lists produced by academics without lab ties. Scalable oversight and debate approaches, by contrast, appeared more frequently in lists originating from UC Berkeley and NYU.
If you're a new PhD student and your entire exposure to alignment comes through one of those lists, you might finish it thinking alignment is mostly about SAEs and circuit analysis. You'd miss whole subfields that have been running for five years., A safety researcher at a major AI lab, speaking on background
The question of what belongs in the alignment canon has practical stakes that go beyond academic taxonomy. The reading lists that labs and fellowship programs distribute are, in effect, the curricula that will shape the next cohort of alignment researchers. A student who works through the OpenAI Safety Fellowship bibliography will emerge with a very different mental model of the alignment problem than a student who completes the Anthropic Fellows Program packet. The OpenAI list, according to three people who have reviewed both, places heavier emphasis on reinforcement learning from human feedback, scalable oversight, and the theoretical foundations of reward modeling. The Anthropic list leans into mechanistic interpretability, conceptual work on deception and situational awareness, and the empirical study of model generalization. The differences are substantive, and they map cleanly onto each lab's internal research priorities.
This would be less consequential if the alignment field had a shared understanding of what success looks like. It does not. One of the few empirical claims that appears in nearly every reading list is that 'alignment is not a single technical problem but a cluster of interrelated problems,' a formulation that traces back to a widely-cited 2022 position paper. But the lists disagree sharply on which of those interrelated problems is most urgent, which is tractable, and which might be rendered irrelevant by advances in model capabilities. The resulting fragmentation has produced what one red-team contractor described to me as 'epistemic tourism': junior researchers who hop between reading lists, absorbing the vocabulary of each subfield without committing to any, because committing to one feels like betting against the others.
The literature review as a genre has itself become an object of study. In February, a team at the University of Cambridge posted a meta-review that analyzed thirty-one alignment-related literature reviews published between 2022 and early 2026. The Cambridge paper, co-authored by researchers in the university's computational linguistics group, applied bibliometric methods to track citation patterns, author networks, and topic clustering across the alignment literature. Among its findings: the field's citation graph shows a pronounced 'core-periphery' structure, with a dense cluster of highly-cited papers anchored by a small number of labs and a long tail of papers that receive few citations outside their immediate subfield. The Cambridge team also found that alignment papers cite work from outside the field at roughly half the rate of comparable papers in machine learning, a pattern they described as 'intellectual insularity that exceeds what can be explained by the field's youth.'
The insularity critique lands differently depending on whom you ask. Researchers who have been in alignment since before the 2022 capability explosion tend to see the tight citation patterns as a feature, not a bug: the field developed its own conceptual vocabulary precisely because mainstream ML's vocabulary was insufficient for the problems alignment researchers were trying to frame. Others argue that the insularity is starting to hurt the field's credibility with the broader ML community, and that it limits the pool of researchers who might contribute useful methods from adjacent areas.
The torrent of new reading lists has also surfaced a quieter tension around who gets to curate them. Nearly every major alignment reading list published since 2023 was assembled by researchers at Western institutions, and the lists' citation patterns skew heavily toward papers authored by researchers at the same handful of labs: Anthropic, DeepMind, OpenAI, MIRI, and a cluster of academic groups at Berkeley, Stanford, Oxford, and Cambridge.
Some organizations have begun to acknowledge the problem. The Alignment Research Center's updated prerequisites document now includes a short section on 'non-Western alignment perspectives,' though the section currently contains only three papers. Anthropic's fellowship application page notes that applicants are not required to have prior familiarity with the lab's preferred reading list. OpenAI's Safety Fellowship takes a different approach: fellows propose their own research agenda, and the reading list is presented as optional background rather than a prerequisite canon. None of these adjustments fully address the underlying dynamic, but they represent an acknowledgment that the lists are doing more than just recommending papers.
The ongoing scrutiny of OpenAI's safety practices, intensified by the Musk lawsuit proceedings that have spilled internal communications into public view, has added a layer of political weight to the reading list question. Documents released as part of the discovery process in April show that OpenAI's safety team, before its well-documented attrition in 2024, maintained an internal reading list that was significantly longer and more technically demanding than the version ultimately released to fellowship applicants. The internal list included papers on deceptive alignment, gradient hacking, and multi-agent failure modes that the public list omits. Two former employees described a process of external-facing safety materials being 'streamlined' for public consumption.
The gap between internal and public-facing reading lists is not unique to OpenAI. Internal alignment curricula at other major labs contain papers and problem framings that the labs have chosen not to emphasize publicly, either because the work is considered preliminary, because it touches on capabilities-sensitive topics, or because it would generate unwanted media attention. One researcher described a roughly sixty percent overlap between the reading list given to fellows and the list used to train new hires, with the remaining forty percent covering topics that are "legitimate alignment research but bad optics." One such topic cited was a paper on the theoretical conditions under which an AI system might have incentives to manipulate its own reward signal, a topic that appears in none of the publicly available reading lists reviewed but in all three of the internal lists referenced.
The opacity problem cuts both ways. If public reading lists are sanitized versions of what alignment researchers actually believe is important, then the field's public-facing canon is systematically misleading. But if internal lists are simply the public lists plus speculative or preliminary work that has not yet been validated, then the gap is a reasonable editorial filter. The difficulty is that outsiders cannot tell which explanation applies in any given case.
Amid all of this, a handful of efforts have emerged to build reading lists that are intentionally cross-cutting and lab-agnostic. The most prominent is the Alignment Open Syllabus, a community-maintained document hosted on GitHub that aggregates papers from every major reading list and weights them by frequency of appearance, with an editorial policy that explicitly excludes papers authored solely by researchers at a single lab. The Open Syllabus, now in its third major version, has been cited by several university courses on AI alignment and was adopted this spring by a new European research consortium as its default curriculum. The project's lead maintainer, a postdoc at ETH Zurich, said that the goal was not to produce the 'correct' reading list but to produce one that 'makes its biases explicit and correctable.'
The Open Syllabus approach has its own critics, who argue that flattening the alignment literature into a frequency-weighted consensus obscures the genuine theoretical disagreements that make the field interesting. This critique has some force, though it assumes that new researchers are looking to reading lists for a position rather than for a map of the terrain. The Open Syllabus maintainer acknowledged the tension: 'A map has to be simpler than the territory. The question is which simplifications are least distorting.'
The recent $150 million funding round for Goodfire, a startup building interpretability tooling, underscores another dimension of the reading list problem: the lists are struggling to keep pace with the commercialization of alignment-adjacent research. Goodfire's platform, which allows users to probe model internals without requiring deep technical expertise, was cited in exactly zero of the reading lists reviewed, because it was announced in February 2026 and most of the lists were compiled before that. But the tool represents a genuinely new capability that changes what kind of alignment research is practical for small teams. The reading list as a genre, with its emphasis on papers and preprints, is structurally slow to incorporate product releases, open-source tooling, and the kind of empirical work that happens outside the preprint ecosystem.
The reading list moment is not permanent. As the alignment field matures, the canonical surveys will stabilize, the citation graph will thicken, and the lists will converge on a shared core, or they will not. The more interesting possibility is that they will not, that the field's intellectual fragmentation is not a symptom of immaturity but a reflection of the genuine difficulty of the alignment problem, which resists reduction to a single framework. If that is the case, then the proliferation of reading lists is not a problem to be solved but a signal to be read. The lists tell us what their authors believe, and the gaps between them tell us where the disagreements are sharp enough that consensus cannot paper them over. For a new researcher trying to find their footing, the gaps are more informative than the consensus. The Toronto table, with its eleven overlapping papers and three hundred eighty-nine singletons, may turn out to be the most honest document the alignment field has produced this year. Watch for the next version.
Read next
