RLHF to RLAIF: The Post-Training Migration Reshaping AI Labs
As AI labs shift from RLHF to RLAIF and constitutional AI, org charts, compute budgets, and alignment definitions are being redrawn—and the labs that master the transition may dictate the next generation of foundation models.
 ai-alignment-and-rationality.github.io
ai-alignment-and-rationality.github.io
In this article
The Feedback Pipeline
To understand why that April morning landed the way it did, it helps to trace the org chart of a modern post-training team. Three years ago, the layout was straightforward: pre-training produced a raw model, and a phalanx of human raters — contractors, mostly, managed by a half-dozen full-time researchers — scored pairwise comparisons of model outputs. Those scores fed a reward model, which in turn fine-tuned the base model via reinforcement learning. The entire pipeline was called RLHF, and by early 2024 it had calcified into industry orthodoxy. But as Sophie Ireland reported for CEOWORLD magazine last month, 'The scalability of human feedback hits a wall when output complexity exceeds what a single rater can evaluate in under thirty seconds.' That wall arrived quietly around mid-2025, when models began generating multi-paragraph reasoning chains that defied rapid pairwise judgment.
We spent three years optimizing for helpfulness scores. Now we're discovering those scores encoded a very narrow slice of human preference — mostly what a tired contractor in a low-wage market considers 'helpful' at 3 p.m. on a Tuesday.— Post-training research lead at a foundation-model lab, speaking on background
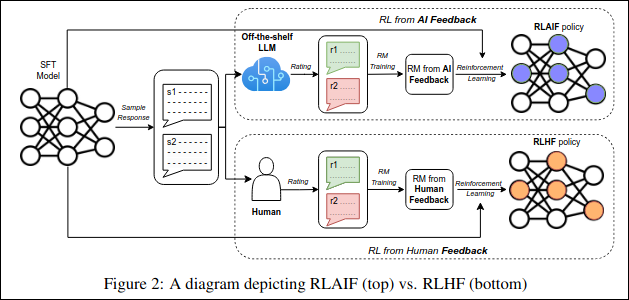
The researcher, one of four current and three former employees who spoke to TechReaderDaily for this story, described a growing recognition across labs that RLHF's real bottleneck was never compute — it was the finite bandwidth of human attention. That recognition has opened the door to two competing, sometimes overlapping, alternatives: RLAIF, which replaces human raters with a larger, already-aligned model to generate feedback; and constitutional methods, which encode principles directly into the training objective so the model self-corrects against a written rulebook. Anthropic's April disclosure tipped the balance toward the latter for many teams watching from the sidelines.
The Org Chart Before and After
Post-training teams that once looked like a pyramid — a few researchers atop a wide base of human raters — are flattening. Two labs, whose internal restructuring plans were described to TechReaderDaily, have cut human-rater headcount by roughly 30 percent since January 2026, redirecting those budgets toward compute for RLAIF pipelines and toward hiring 'constitution designers' — researchers who draft and maintain the written principles that govern constitutional training runs.
The conversation is no longer about how much compute you pour into pre-training. It's about who designs your reward function and what values it encodes.
The shift carries implications that extend well beyond lab benches. As MIT Technology Review noted in March, 'As LLM scaling hits diminishing returns, the next frontier of advantage is the institutionalization of proprietary logic.' The piece, published in partnership with Mistral AI, argued that domain-specialized intelligence — not bigger pre-training runs — now delivers the step-function improvements enterprises actually care about. Post-training methodology is the engine of that specialization. RLHF, RLAIF, and constitutional methods are not academic debates; they are the toolchain that determines whether a model deployed in a hospital gives different advice than one deployed in a law firm.
The Bet
Amazon's $33 billion commitment to Anthropic, announced in late April, can be read as a bet on exactly this transition — not just on Anthropic's models but on its post-training methodology. Constitutional AI is the laboratory's signature approach, and Amazon's compute pledge effectively finances scaling it to models far larger than any lab has attempted with RLAIF pipelines. But it is also a bet with a deadline. Two cloud account managers who negotiate compute contracts for AI labs told TechReaderDaily that reserve-instance pricing for the GPU clusters required to run RLAIF at frontier scale has risen roughly 40 percent since Q3 2025. The window to lock in affordable training is closing.
By early May 2026, the question inside post-training teams was no longer which methodology wins — most labs are now running hybrid pipelines that combine human feedback, AI feedback, and constitutional guardrails in varying proportions — but rather who gets to decide the blend, and on what timeline.
- RLHF remains the default for consumer-facing chat models but faces a scaling ceiling as outputs grow more complex.
- RLAIF, pioneered by Anthropic and now adopted in hybrid form at three major labs, removes human latency but introduces model-to-model drift risks.
- Constitutional methods encode principles directly into training objectives — a shift that turns alignment from a statistical problem into an editorial one.
The Slack thread from that April morning is still open in at least one lab. The last message in it, posted at 11:43 p.m. on May 8, asked whether the team's 2027 post-training roadmap assumed a written constitution, an AI-written constitution, or no constitution at all. No one had replied when this story went to press.
Read next
