Stateful Workflow Engines Build Trustworthy AI Agent Infrastructure
Cloud providers and startups are racing to build agent-native infrastructure that remembers, recovers, and replays, making this year's architecture decisions critical for which AI agents earn production trust.
 aws.amazon.com
aws.amazon.com
In this article
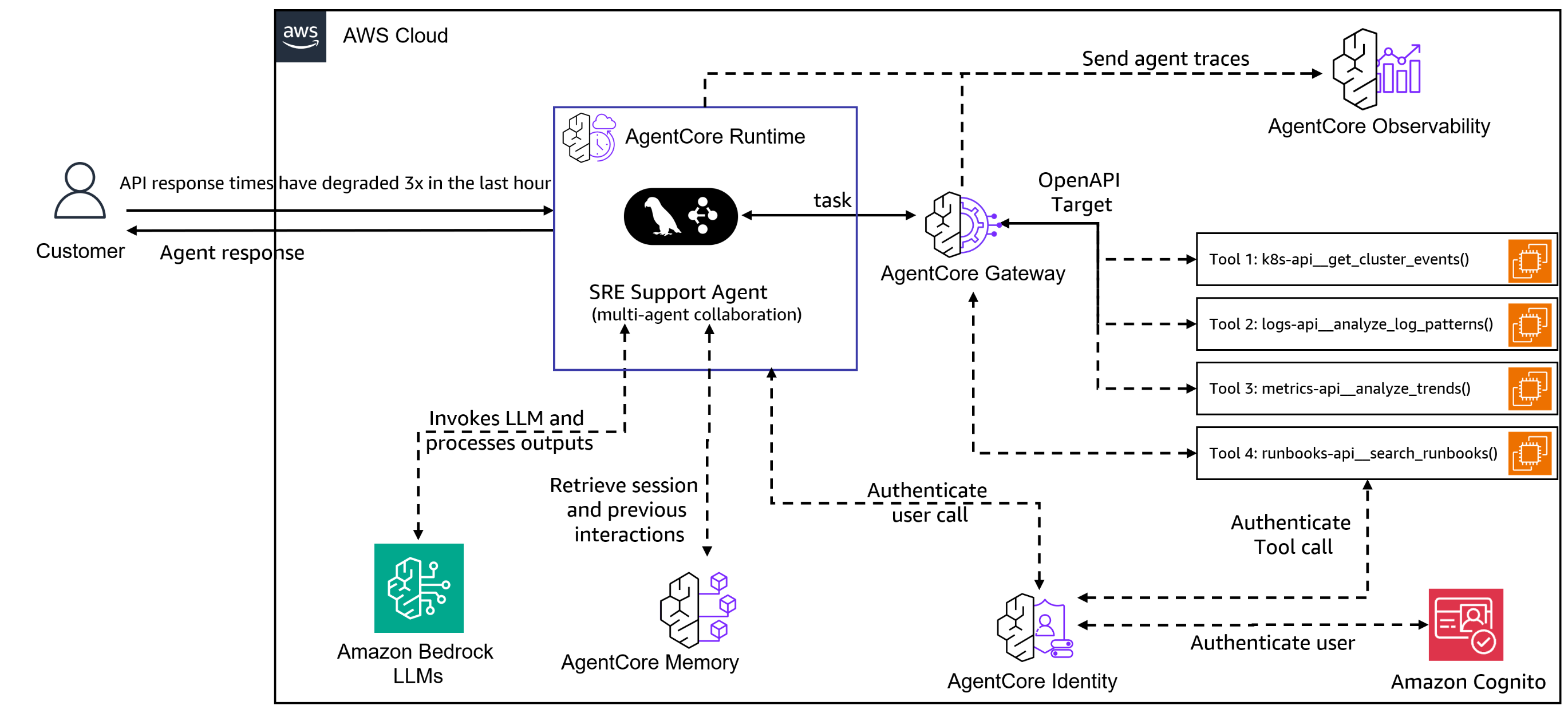
On April 22, 2026, Amazon Web Services shipped an update to Bedrock AgentCore that reduced the ceremony of deploying an autonomous AI agent to three API calls: one to define the agent, one to attach a model, and one to wire in a tool. The change, covered by Forbes and SiliconANGLE, also introduced a managed agent harness, a dedicated CLI, and a persistent filesystem that survives across invocations. Three API calls is a number chosen to make a point. The previous workflow demanded manual wiring of Lambda functions, Step Functions state machines, and IAM role scaffolding that could take an experienced platform engineer the better part of a day. Compressing that to three calls signals that AWS now considers the agent runtime a first-class primitive, not a composition of existing serverless parts. But the architectural shift underneath those three calls is larger than a product launch. It marks the moment the industry started treating the agent as the workload, not the application that wraps a model call.
The shorthand for what is happening is this: the serverless paradigm, built on the assumption that compute is stateless and ephemeral, is being retrofitted for workloads that are inherently stateful, long-running, and conversational. An agent that researches a procurement decision across six internal APIs, pauses to wait for a human approval, resumes with new context, and replays its reasoning trail when audited does not fit inside a 15-minute Lambda timeout or a Cloud Run request-response envelope. The infrastructure industry spent the first half of 2026 coming to terms with that mismatch, and the result is a new category of tooling that borrows heavily from an old database idea, durable execution, while scrambling to graft it onto the model-serving stack that has dominated cloud investment since late 2022.
The most legible forcing function arrived in late April when VentureBeat reported that Mistral AI had launched a workflow orchestration engine called Workflows, built on Temporal, already processing millions of daily executions inside enterprise deployments. For readers who have not spent time with Temporal's architecture, the short version is that it is a durable execution engine: it persists every step of a workflow to an event log, so if the process crashes mid-flight, it can be replayed deterministically from the last checkpoint. That property, which database engineers have relied on since the write-ahead log was formalized in the 1980s, is suddenly the most sought-after feature in the AI stack. An agent that cannot replay its reasoning chain after a crash is an agent that cannot be debugged, cannot be audited, and cannot be trusted with a purchasing decision or a customer-facing escalation.
Mistral's choice of Temporal is instructive because it bypasses the cloud providers' native orchestration layers entirely. Rather than building on AWS Step Functions or Google Cloud Workflows, Mistral embedded an open-source durable execution runtime directly into its platform and exposed it to customers as a managed service. The implication, whether Mistral intended it or not, is that the first generation of cloud-native workflow engines was designed for a world where the unit of work was a containerized microservice with a predictable execution boundary. An LLM agent calling tools, reflecting on results, and replanning mid-flight does not have a predictable execution boundary. Its runtime is shaped like a conversation, not a function graph.
Across the three major clouds, the response to this architectural pressure has been anything but uniform. Microsoft released version 1.0 of its Agent Framework on April 3, an attempt to unify two previously separate agent SDKs, AutoGen and the Copilot Studio agent runtime. Forbes analyst Janakiram MSV wrote that the result was a stack spanning too many surfaces: the Agent Framework itself, the Copilot Studio low-code layer, the Foundry Agent Service for enterprise deployment, and a separate set of governance controls inside Entra ID. A developer who wants to ship a single agent to production must navigate at least four Azure consoles, each with its own pricing model and its own opinion about how agent state should be managed. MSV contrasted this with Google Cloud's Agent Development Kit, which ships as a single open-source Python framework that deploys to Vertex AI Agent Engine with a unified command, and AWS Strands, which exposes the AgentCore harness through the Bedrock SDK and a CLI that is deliberately thin.
The fragmentation is not cosmetic. When an agent framework forces the developer to choose upfront whether state lives inside the model context window, in an external vector store, or in a workflow engine's event log, the choice determines every failure mode the system will exhibit later. A model-context-only agent will lose its memory the moment a conversation exceeds the context limit. A vector-store agent will silently retrieve stale facts when the underlying data changes. A workflow-engine agent will survive crashes but will struggle to incorporate unstructured human feedback that arrives outside the defined state machine. The cloud provider that picks one of these patterns as the default, and hides the others behind configuration flags, is making an opinionated bet on which failure mode its customers will find most tolerable.
The agent registry, a concept that barely existed in January, has become the surface where these architectural bets are made visible. Forbes reported on April 10 that AWS, Microsoft, and Google are all building agent governance layers that serve as discovery and control planes for fleets of autonomous agents. AWS launched its Agent Registry inside Bedrock AgentCore, tying each registered agent to an IAM role and a set of allowed tool invocations. Microsoft followed with Agent 365, which registers agents in Entra ID and applies Conditional Access policies to agent-to-agent communication. Google Cloud's API Registry, the most developer-centric of the three, treats agents as versioned API endpoints with OpenAPI specifications, reflecting Google's bet that agent governance will converge with API governance over time.
The battle over discovery and control of AI agent fleets is just beginning., Janakiram MSV, cloud analyst, writing in Forbes, April 10, 2026
The governance question is not academic. ServiceNow used its Knowledge 2026 conference in early May to expand what it calls an AI Control Tower, a centralized dashboard for monitoring agent behavior, enforcing access policies, and auditing decisions across its platform. Forbes noted that ServiceNow is betting enterprise buyers will pay a premium for a governance layer that sits above whatever agent runtime their developers choose, a hedge against the fragmentation that Microsoft's multi-surface strategy has already produced. ServiceNow's position, echoed by several platform vendors this spring, is that the agent runtime matters less than the control plane that governs it, a claim that would be more convincing if every control plane did not assume a different model for how agent state is stored, versioned, and replayed.
Beneath the product announcements, a deeper redefinition is underway. The term "AI-native cloud" has begun appearing in vendor marketing, most prominently from DigitalOcean, which unveiled a five-layer AI-Native Cloud platform at its Deploy 2026 conference in late April. Forbes covered the launch, describing an Inference Engine for model serving, a model router that selects the cheapest capable model for each request, and a set of managed agents aimed at small and medium businesses that DigitalOcean argues have been priced out of the hyperscaler AI stacks. The platform is interesting less for its individual components than for its implicit argument: that the cloud-native primitives of the 2010s, containers, Kubernetes pods, serverless functions, are insufficient abstractions for workloads whose primary resource is not CPU cycles but context.
Context density is the term that has begun to circulate in conference talks and architecture reviews. SiliconANGLE reported from KubeCon EU 2026 in late March that the Cloud Native Computing Foundation's flagship event was dominated by discussions of how to measure, store, and transfer the dense bundles of structured and unstructured data that agents accumulate during multi-step reasoning. A Kubernetes pod is designed to be cattle, not pet; it carries just enough configuration to boot and connect to its dependencies. An agent, by contrast, arrives at each step of a workflow carrying the accumulated weight of every previous step: the original user prompt, the results of three tool calls, a chain-of-thought trace, a human approval token, and a revised plan. That bundle, which can easily exceed a megabyte of JSON even for a moderately complex procurement workflow, does not fit cleanly into etcd or a ConfigMap.
The operational implications become stark when you examine what happens under failure. An agent that times out after 14 minutes of a 20-minute research loop must be resumable from the exact point of interruption, with all intermediate state intact, or the work is wasted and the user receives a partial answer. This is a problem that database engineers solved decades ago with checkpointing and write-ahead logging, but the model-serving infrastructure built since 2022 was not designed with checkpointing in mind. Most inference endpoints are stateless by design, a choice that made them easy to scale horizontally but left the burden of state management entirely on the application layer. The result, visible in the architecture of every major agent framework that shipped in the first half of 2026, is that the application layer is rapidly absorbing database responsibilities, and doing so unevenly.
What the Serverless Pivot Actually Means
Google Cloud Run's pivot toward AI workloads, reported by MSN on May 10, illustrates the tension. Cloud Run added ephemeral storage and remote MCP (Model Context Protocol) server capabilities, features that allow a serverless container to maintain state across the duration of an agent session without provisioning a persistent database. The additions are pragmatic but they pull Cloud Run away from its original design philosophy, which treated each request as an independent event that could be routed to any available instance. An agent session pinned to a specific instance with local ephemeral storage is no longer truly serverless in the architectural sense; it has become a stateful actor with a preferred locality, a pattern that the actor model formalized in the 1970s and that cloud platforms spent two decades trying to abstract away.
Vercel faces a parallel challenge. The same MSN report noted that Vercel's delayed disclosure of a security incident had shaken confidence in its platform just as edge functions were being repositioned for agentic workloads. Edge platforms, which execute code close to users in dozens of global locations, are attractive for agent workloads that need low-latency tool calls to geographically distributed APIs. But edge functions inherit the same stateless assumption that serverless platforms are now struggling to shed. Running a stateful agent on the edge requires either a centralized state store that reintroduces latency, or a distributed consensus mechanism that few edge platforms have implemented. The engineering tradeoff is not yet settled, and the security incident reporting suggests that the operational maturity of these platforms is lagging behind their architectural ambition.
The security dimension adds another layer of urgency. At RSAC 2026, VentureBeat reported, CrowdStrike CEO George Kurtz warned that the fastest recorded adversary breakout time had dropped to 27 seconds, with the average falling to 29 minutes from 48 minutes a year earlier. The statistic was delivered as justification for agentic SOC tools, autonomous security agents that can detect and contain threats faster than a human analyst. CrowdStrike, Cisco, and Palo Alto Networks all shipped agentic SOC capabilities at the conference. But VentureBeat noted that all three products shared a common gap: they lacked a behavioral baseline for the agents themselves. A security agent that can modify firewall rules and rotate credentials is a high-privilege actor. Without a durable, auditable execution log, its actions are indistinguishable from an attacker's lateral movement.
This is the argument that connects the database architecture of Temporal to the security keynote at RSAC and the governance dashboard at ServiceNow's conference. The durable execution log is not just a reliability feature. It is the only artifact that can answer the question "what did the agent actually do?" after a security incident. A platform that can replay every tool invocation, every model call, and every human approval in deterministic order can produce an audit trail that a SOC team can trust. A platform that cannot replay is asking the organization to trust a black box, and organizations that have spent two decades building SOCs and compliance regimes around deterministic, auditable systems are unlikely to accept that tradeoff for long.
What to Watch For
Three signals will indicate how this architectural debate resolves before the end of 2026. The first is whether any of the major cloud providers ships a managed durable execution service that is priced and packaged for agent workloads, not for microservice orchestration. AWS Step Functions and Google Cloud Workflows exist but were designed for a different era; their pricing models assume hundreds of state transitions per execution, not the thousands that a reflective agent loop can generate in a single conversation. A purpose-built agent workflow service, with per-token or per-session pricing rather than per-state-transition pricing, would signal that the provider understands the economics of the new workload.
The second signal is consolidation around the MCP (Model Context Protocol) as the standard for agent-to-tool communication. MCP, which originated at Anthropic and has been adopted by a growing number of infrastructure vendors, provides a uniform interface for agents to discover and invoke tools, including tools that themselves are agents. If MCP becomes the de facto standard, it will simplify the registry and governance problem by giving every agent a common discovery mechanism. If it fragments, the multi-surface problem that Microsoft's stack already exhibits will become endemic across the industry.
The third signal is the emergence of an incident postmortem from a major enterprise that attributes a material loss to an untrustworthy agent audit trail. This has not happened yet in a publicly documented form, but the conditions are present: agents are being deployed with spending authority, with access to customer data, and with the ability to modify production infrastructure. When the first agent-driven incident occurs and the response team discovers they cannot determine what the agent did or why, the market for durable execution will stop being an architectural preference and start being a compliance requirement. The vendors who have already built their platforms around replayable event logs will not need to retrofit. The vendors who treated state as an application-layer concern will have to explain why their agents cannot be audited.
The phrase "agent-native runtime" entered the industry lexicon in early 2026 not because anyone coined it in a keynote, but because the existing runtimes were visibly straining under workloads they were never designed to carry. A Lambda function was designed to run for a few seconds, transform an event, and exit. An agent was designed to run for minutes or hours, remember what it learned, and keep going. The infrastructure industry is now doing what it always does when a new workload arrives: it is rediscovering old database ideas, repackaging them for a new audience, and calling the result a platform. Whether the result is called Bedrock AgentCore, Temporal, or something that has not yet shipped, the design constraint is the same. The runtime is the agent, and the agent is stateful, or it is not an agent at all.
Read next
