 AI · Leaderboard Mechanics
AI · Leaderboard Mechanics
DeepSWE's coding audit and Microsoft's MDASH multi-agent system expose how mid-2026 leaderboard shakeups reveal a growing chasm between benchmark scores and real-world AI capability.
Jun 21, 2026
·
10 min
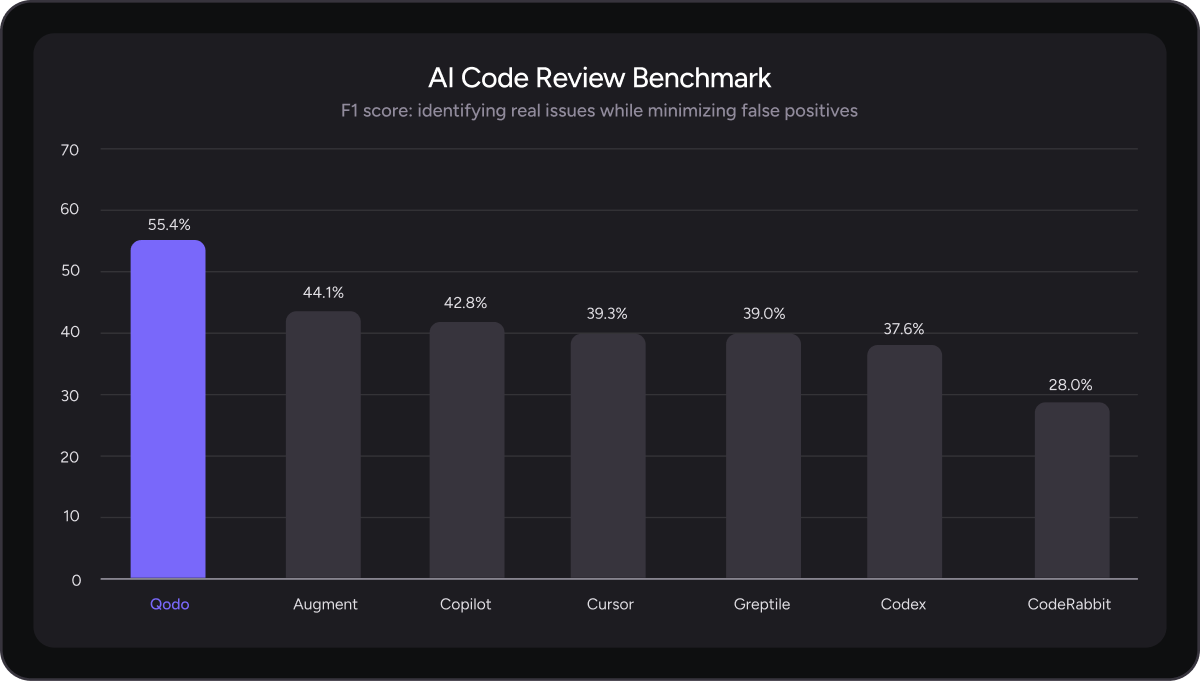 Evaluation · Benchmarks
Evaluation · Benchmarks
Datacurve's DeepSWE benchmark scattered the AI coding leaderboard by revealing that SWE-Bench Pro rewarded pattern-matching instead of engineering reasoning, a finding that enterprise buyers are now using to reassess their model choices.
Jun 11, 2026
·
9 min
 Open Weights · Licensing
Open Weights · Licensing
Google's release of Gemma 4 under Apache 2.0 ends the open-weight licensing standoff, shifting pressure to labs still shipping models with custom restrictions.
May 22, 2026
·
9 min
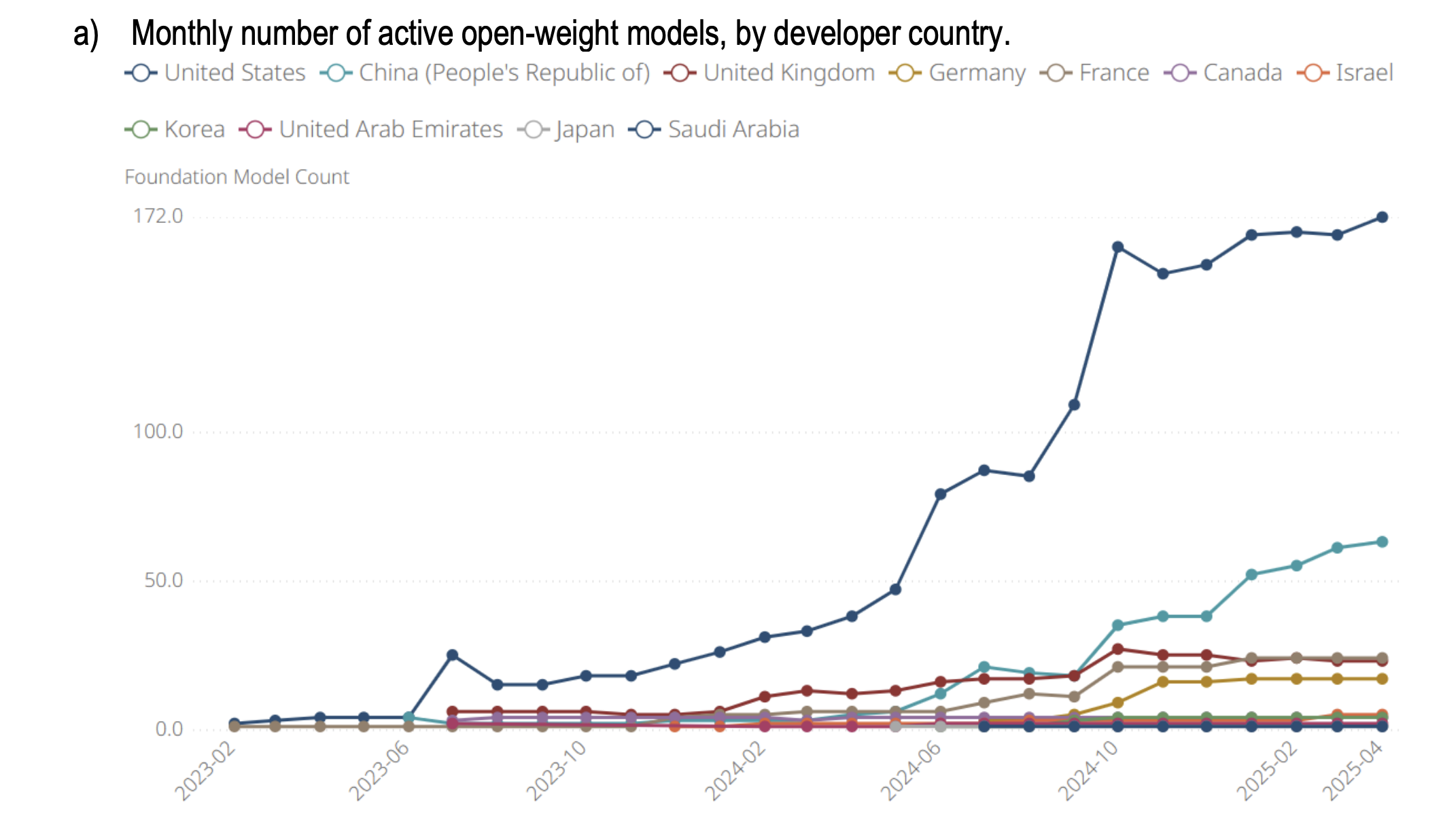 Regulation · Open Weights
Regulation · Open Weights
After months of deadlocked trilogue negotiations, Brussels softened the EU AI Act, giving open-weight model providers carve-outs that matter more than the looming compliance deadlines.
May 17, 2026
·
7 min
 Open Weights · Regulation
Open Weights · Regulation
Brussels secured a 16-month extension for high-risk AI rules, but the clear open-weights carve-out that model providers demanded remains absent from the Omnibus deal.
May 14, 2026
·
9 min
 Policy · Open Weights
Policy · Open Weights
The May 2026 deal grants open-weights releases another 18 months of lighter-touch regulation, yet the definition of 'open source' qualifying for the carve-out remains unsettled, and Meta's pivot to proprietary models signals that the big labs are already hedging.
May 13, 2026
·
9 min
 AI · Open Weights
AI · Open Weights
Google’s decision to release Gemma 4 under the permissive Apache 2.0 license reshuffles the open-weights landscape, putting immediate pressure on Meta’s Llama and any other lab still shipping models with restrictive usage terms.
May 12, 2026
·
9 min
 AI · Evaluation
AI · Evaluation
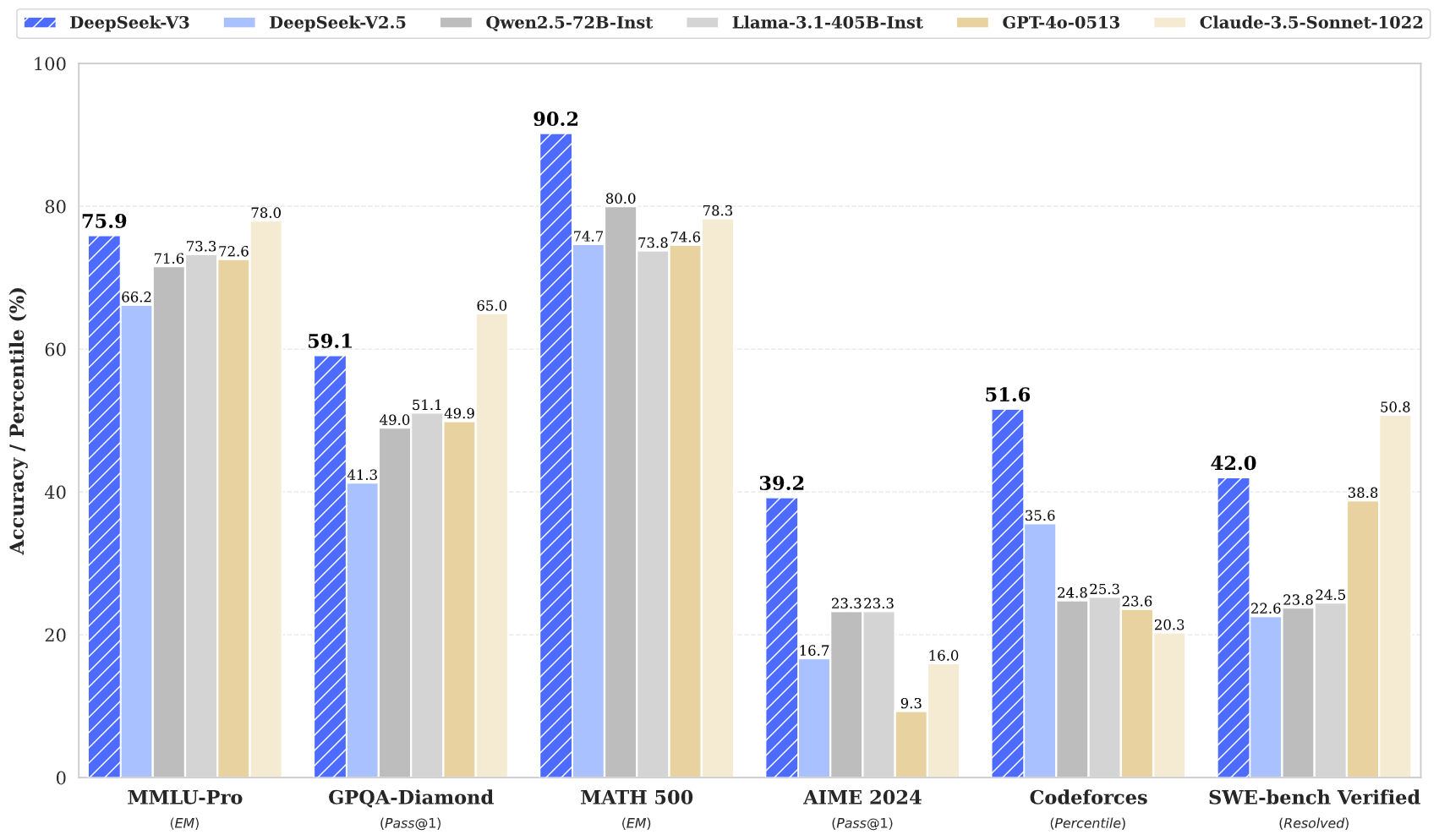
From SWE-Bench Pro to the Stanford AI Index, AI benchmark leaderboards now drive billions in investment and geopolitical posturing, yet the mechanics behind the numbers are more fragile than the scores suggest.
May 11, 2026
·
8 min
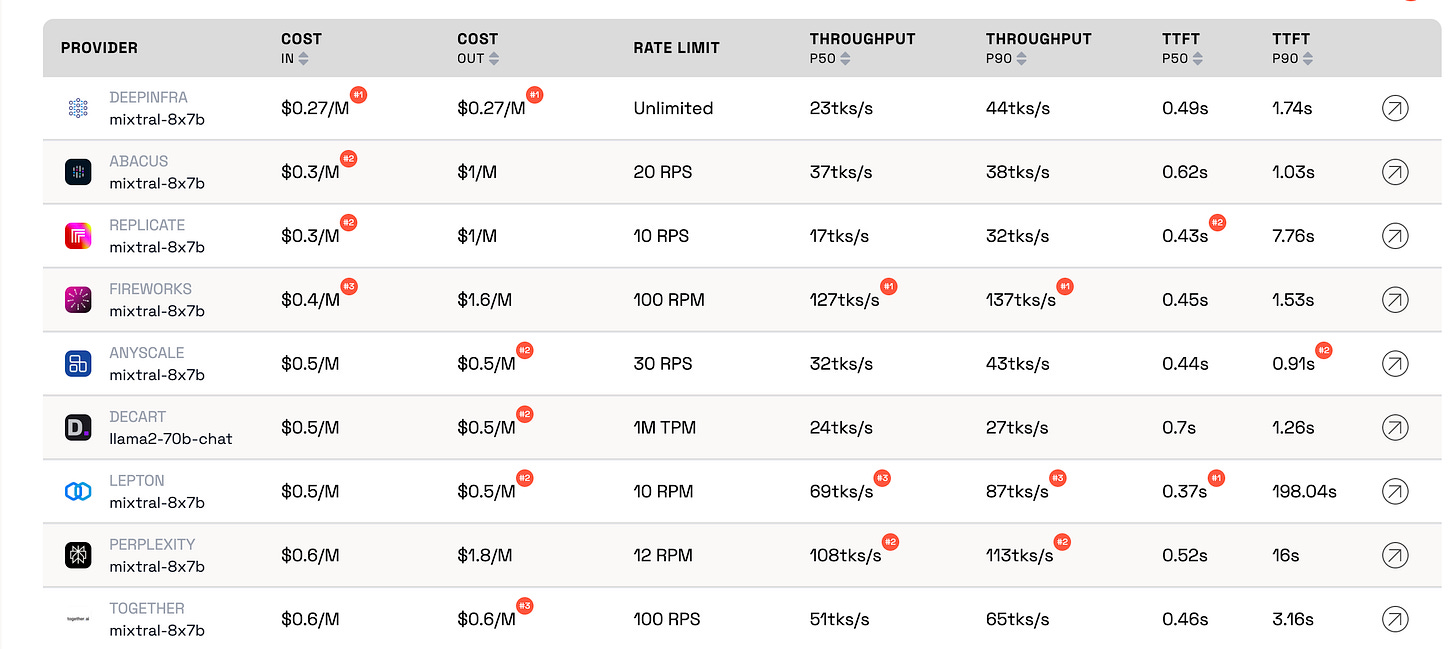 AI Desk · Benchmarks & Evaluation
AI Desk · Benchmarks & Evaluation
From drug discovery to code generation, benchmark leaderboards have become the scorecard for AI progress, but a rash of contamination scandals, domain mismatches, and license shell games is forcing the community to confront what these rankings actually measure.
May 9, 2026
·
11 min
 Open Weights · Evaluation
Open Weights · Evaluation
As the gap between leaderboard-topping scores and deployable models widens, researchers are questioning whether these benchmarks actually measure what matters for real-world AI performance.
May 9, 2026
·
3 min
 AI · Open weights
AI · Open weights
No press release, no blog post, no Twitter thread. Just a Hugging Face commit and a one-paragraph model card. The license terms are the part you should actually read.
May 8, 2026
·
1 min
 AI · Open weights
AI · Open weights
Three of the four open-weights releases of the past 30 days share the same five clauses. The Brussels Effect is now a license template, and developers should read it before downloading.
May 7, 2026
·
1 min
