DAST-SAST Correlation Engine Arrives as AI Rewrites Code Scanning
As Invicti's correlation engine maps runtime vulnerabilities to source code, AI reasoning models from Anthropic and OpenAI enter static analysis, accelerating the convergence of AppSec testing tools.
 www.blackduck.com
www.blackduck.com
In this article
On April 9, 2026, Invicti announced a capability that application security engineers have been requesting for the better part of a decade: automated correlation between dynamic application security testing (DAST) findings and the static analysis (SAST) results that point developers to the exact line of code where a vulnerability originates. The Austin-based vendor called it DAST-to-SAST correlation, and positioned it as a way for DevOps teams to fix verified runtime risks at pipeline speed, according to a press release issued that morning.
The announcement landed two weeks after a webinar hosted by GovInfoSecurity and HHS asked whether AI was finally making DAST-to-SAST correlation possible, framing the question as the brass ring of the application security discipline. The timing was not a coincidence. For years, the two testing methodologies have operated in separate silos, producing overlapping but rarely intersecting lists of findings that security teams triage manually, often with spreadsheets and intuition rather than tooling.
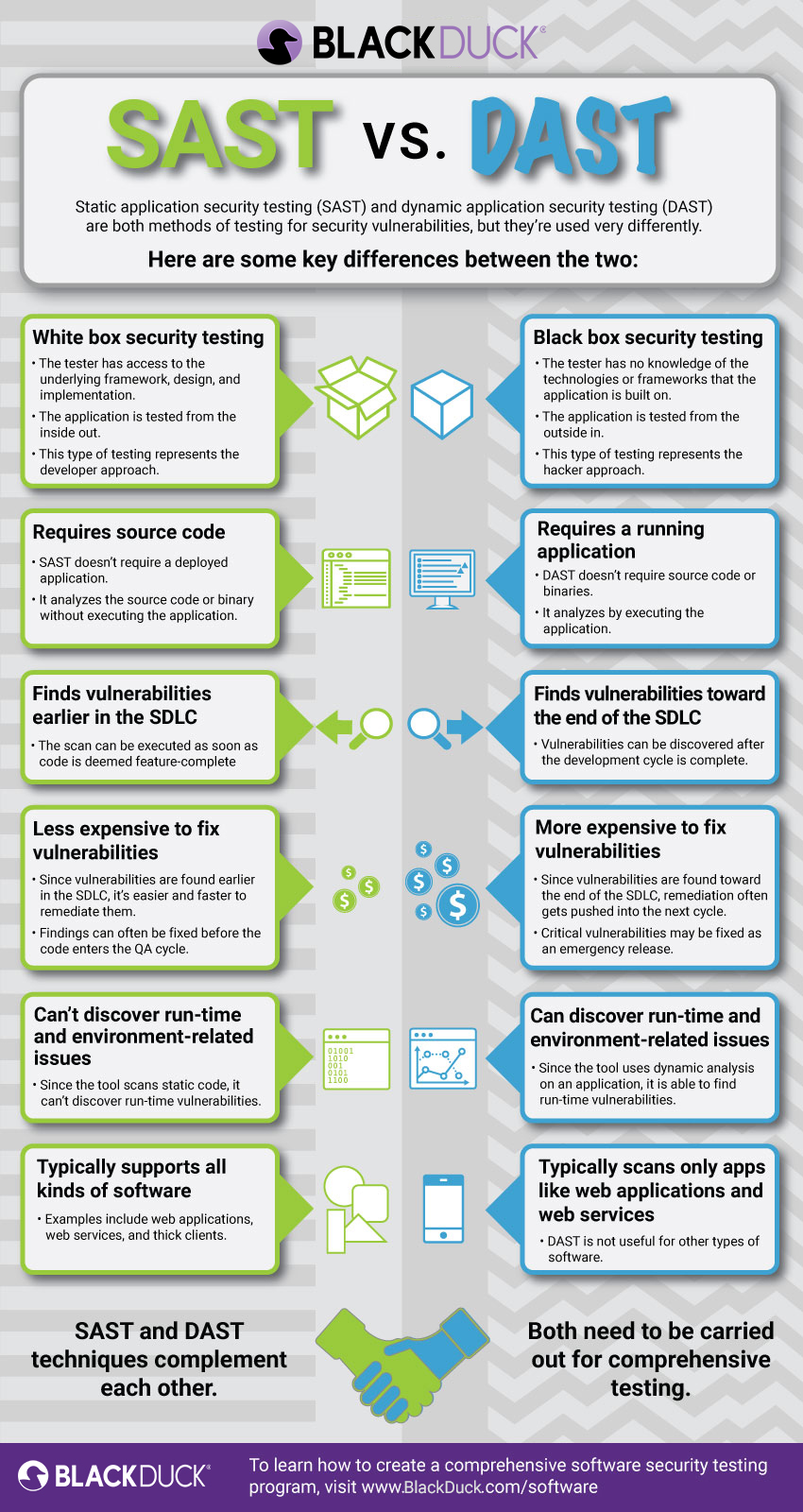
The structural gap is well understood inside the industry. SAST scans source code, bytecode, or binary artifacts before the application runs, flagging patterns that match known vulnerability classes such as SQL injection, cross-site scripting, or insecure deserialization. DAST operates against a running application, sending malicious payloads and observing responses, confirming whether a suspected flaw is actually exploitable at runtime. The two views answer different questions. SAST asks what might be wrong in the code. DAST asks what is wrong at the network endpoint. For most of the past fifteen years, no commercial tool has reliably bridged the answers.
The Invicti correlation engine attempts to close that loop by taking a DAST-confirmed vulnerability and mapping it backward through the application's attack surface to the source file, line number, and commit history where the defect was introduced. The company, which maintains one of the larger installed bases of DAST scanners through its Netsparker and Acunetix product lines, is betting that development teams will fix vulnerabilities faster when the runtime evidence is tethered directly to the code they need to change. The press release described the capability as designed to help DevOps fix verified runtime risks at pipeline speed, though independent benchmarks of the correlation accuracy have not yet been published.
The announcement was significant less for its technical novelty than for what it signals about the market's direction. Application security has been consolidating toward platforms that promise a unified view of risk across the development lifecycle, from the first commit to the production deployment. Snyk, GitLab, and GitHub have all added SAST, DAST, and software composition analysis modules under single interfaces. Invicti's move adds correlation to a product that already spans both static and dynamic testing, placing it in direct competition with the platform players while differentiating on what happens between the two scan types.
But the Invicti launch is only one thread in a larger unraveling of the traditional SAST market. In February and March of 2026, two of the largest AI labs entered application security with free code-scanning tools that bypass the signature-and-rule-based architecture that has defined SAST for two decades. Anthropic released Claude Code Security on February 20. OpenAI followed with Codex Security on March 6. VentureBeat reported that both scanners use large language model reasoning instead of static pattern matching, marking what the outlet described as a structural challenge to the incumbent SAST vendors.
The distinction matters. Traditional SAST tools rely on a combination of control-flow analysis, data-flow analysis, and taint tracking, implemented as rules maintained by security research teams. Each rule encodes a pattern: an unsanitized parameter passed to a database query, a deserialization call on attacker-controllable input. The rules are precise but brittle. They produce false positives when applied to code patterns that the rule author did not anticipate, and they miss vulnerabilities that do not match any existing rule. Most enterprise SAST deployments produce thousands of findings per scan, of which a small fraction represent exploitable conditions.
LLM-based scanners operate differently. Instead of matching against a catalog of known patterns, they read source code and reason about its security properties using the same transformer architectures that power code generation. Anthropic's Claude Code Security and OpenAI's Codex Security each process entire files or repositories, identify potential weaknesses through semantic understanding, and produce findings with natural-language explanations. The approach is closer to how a human code reviewer works than to how a static analyzer works. The question, still open, is whether it produces fewer false positives or simply different ones.
The AI entrants arrived at a moment when their own parent companies were drawing scrutiny for the security properties of AI-generated code. On April 22, Forbes reported that cyber experts were warning that Anthropic's latest Claude models were introducing serious security issues into code, and noted that the company had yet to officially explain why. The irony was not lost on the security community: the same lab offering a free SAST tool was also shipping models that security professionals said were generating vulnerable code at an elevated rate.
The Forbes report cited unnamed cyber experts, and Anthropic has not publicly addressed the specific claims. But the broader dynamic it highlighted is not in dispute. AI-assisted code generation tools, from GitHub Copilot to Cursor to Claude Code, have accelerated the velocity of software production across the industry. Faster code production means more code to secure, more attack surface to assess, and more findings for security teams to triage. The SAST and DAST tools that were designed for a world of quarterly releases are being asked to operate at the speed of continuous deployment, and the gap between scan cadence and release cadence is widening.
Runtime enters the triad
While the SAST market was being reshaped by LLM entrants, a third category of tooling was quietly gaining ground. Interactive application security testing, or IAST, places instrumentation inside a running application and observes its behavior during functional testing, reporting vulnerabilities only when data flows through an actual exploitable path. Because IAST operates inside the runtime, it produces near-zero false positives. The trade-off is coverage: IAST can only report on code paths that are actually exercised during testing, meaning it requires test suites with high path coverage to be effective.
On March 18, 2026, at JavaOne, Waratek launched its own IAST product with a pointed message. The company's press release stated that AI-assisted code speeds development but introduces vulnerabilities at an alarming rate, and claimed that Waratek IAST reports flaws that are exploitable with 100% accuracy. The company's chief executive, John Adams, was quoted in materials distributed at the conference saying the industry must move beyond trying to scan code for vulnerabilities that may be there, toward instrumenting applications to see which vulnerabilities are actually reachable at runtime.
We must move beyond trying to scan code for vulnerabilities that may be there, toward instrumenting applications to see which vulnerabilities are actually reachable at runtime., John Adams, CEO of Waratek, at JavaOne 2026
The SAST-DAST-IAST triad is not new. Gartner has been categorizing application security testing along these three axes for years, and most large enterprises run tools in at least two of the three categories. What is changing is the velocity of findings, the cost of triage, and the arrival of AI models that can read, write, and now audit code. The question the industry is grappling with, as the GovInfoSecurity webinar framed it in March, is whether AI can finally make the outputs of these three tools correlate in a way that reduces the mean time to remediate rather than simply generating more dashboards.
The systemic version of this single-vendor failure is visible across the industry. Security teams receive SAST findings from one console, DAST findings from a second, software composition analysis alerts from a third, and increasingly IAST telemetry from a fourth. Each tool uses its own severity taxonomy, its own deduplication logic, and its own integration surface. The engineers who are expected to fix the findings work in a fifth system, the code repository, where the connection between a DAST alert and the responsible source file is maintained by institutional knowledge rather than automated correlation. When that institutional knowledge walks out the door, the connection breaks.
The disclosure timeline question is also worth asking. When Invicti shipped its DAST-to-SAST correlation engine in April, it did not publish a detailed accuracy study, a false-positive rate benchmark, or a comparison against manual correlation by experienced security engineers. The press release described the capability in product-marketing terms, and the company's existing customers will be the first to generate data on whether the automated mapping is reliable enough to replace the manual triage workflows that most security programs depend on. That data has not yet surfaced in any public forum.
Meanwhile, Anthropic and OpenAI are moving fast. On April 30, SecurityWeek reported that Anthropic had positioned Claude Security as a countermeasure to the exploit surge it anticipated from its own more capable models, particularly Claude Mythos, an internal security-focused model the company described as too dangerous to release publicly. On May 12, The Verge reported that OpenAI had launched Daybreak, a broader cybersecurity platform that builds on Codex Security and includes specialized cyber models such as GPT-5.5-Cyber, to detect and patch vulnerabilities before attackers find them.
Both AI labs are essentially building application security products on top of the same models that are generating the code those products are designed to audit. The strategic logic is straightforward. If foundation models are producing a growing share of the world's new code, and if those models have known failure modes around security, the lab that ships the best auditor for its own model's output captures a defensive moat while also generating training signal to improve the next generation of code-generating models. Whether this creates a conflict of interest is a question the labs have not addressed publicly.
For the security teams on the receiving end, the near-term implications are practical rather than philosophical. The SAST tools they have been running for years are being augmented, and in some cases displaced, by LLM-based scanners that produce different kinds of findings with different accuracy characteristics. The DAST tools they run against staging and production environments are beginning to correlate findings back to source code automatically. And the IAST tools they may not have deployed yet are offering a third data source that promises higher precision at the cost of runtime overhead. The integration surface is growing faster than the integration logic.
The residual risk is not that organizations will miss a critical vulnerability because they lack tools. It is that they will drown in findings from too many tools, each speaking a slightly different language, and lose the ability to distinguish the five vulnerabilities that matter from the five thousand that do not. Correlation, whether automated by Invicti's engine or inferred by an LLM reading both SAST and DAST outputs, is the problem that sits between detection and remediation. It has been underinvested for a decade. If 2026 is the year that changes, it will not be because any single vendor shipped a feature. It will be because the cost of not correlating finally exceeded the cost of building the plumbing.