Prompt Injection Is AI's New Attack Surface, With No Clear Guardian
With six coding agents breached in nine months and Google disrupting the first AI-developed zero-day, the common thread is a prompt injection attack surface invisible to identity and access management systems.
 paloaltonetworks.com
paloaltonetworks.com
In this article
On May 11, 2026, Google's Threat Intelligence Group disclosed that it had detected and disrupted a criminal group preparing to launch what would have been the first mass exploitation of a zero-day vulnerability discovered and weaponized with the help of an artificial intelligence model. The target was an open-source administrative tool used across thousands of organisations; the exploit was designed to bypass two-factor authentication. Google did not name the vendor, and it did not name the large language model the attackers used. It confirmed only that its own Gemini model was not involved.
The announcement, reported by the Associated Press and detailed further by CSO Online, marks a genuine threshold: the first confirmed instance in which an AI model was used not merely to accelerate the writing of malware, but to reason about a software system's architecture, identify a novel vulnerability, and produce a working exploit against it. The underlying flaw, CSO Online's Lucian Constantin reported, stemmed from a faulty trust assumption in the software, the kind of logic gap that automated fuzzing tools often miss because it requires understanding what a component ought to trust and what it actually does.
The story landed in the middle of a spring that had already delivered a cascade of warnings about the expanding threat surface around AI agents. On May 1, VentureBeat reported that six independent research teams had, over the preceding nine months, successfully exploited Claude Code, GitHub Copilot, OpenAI Codex, and Google Vertex AI. Every single one of those attacks went after the same thing: runtime credentials that Identity and Access Management tooling never tracked. Not one team needed to attack the model itself. The agent's access to secrets, environment variables, and deployment tokens was the prize, and the prompt was the door.
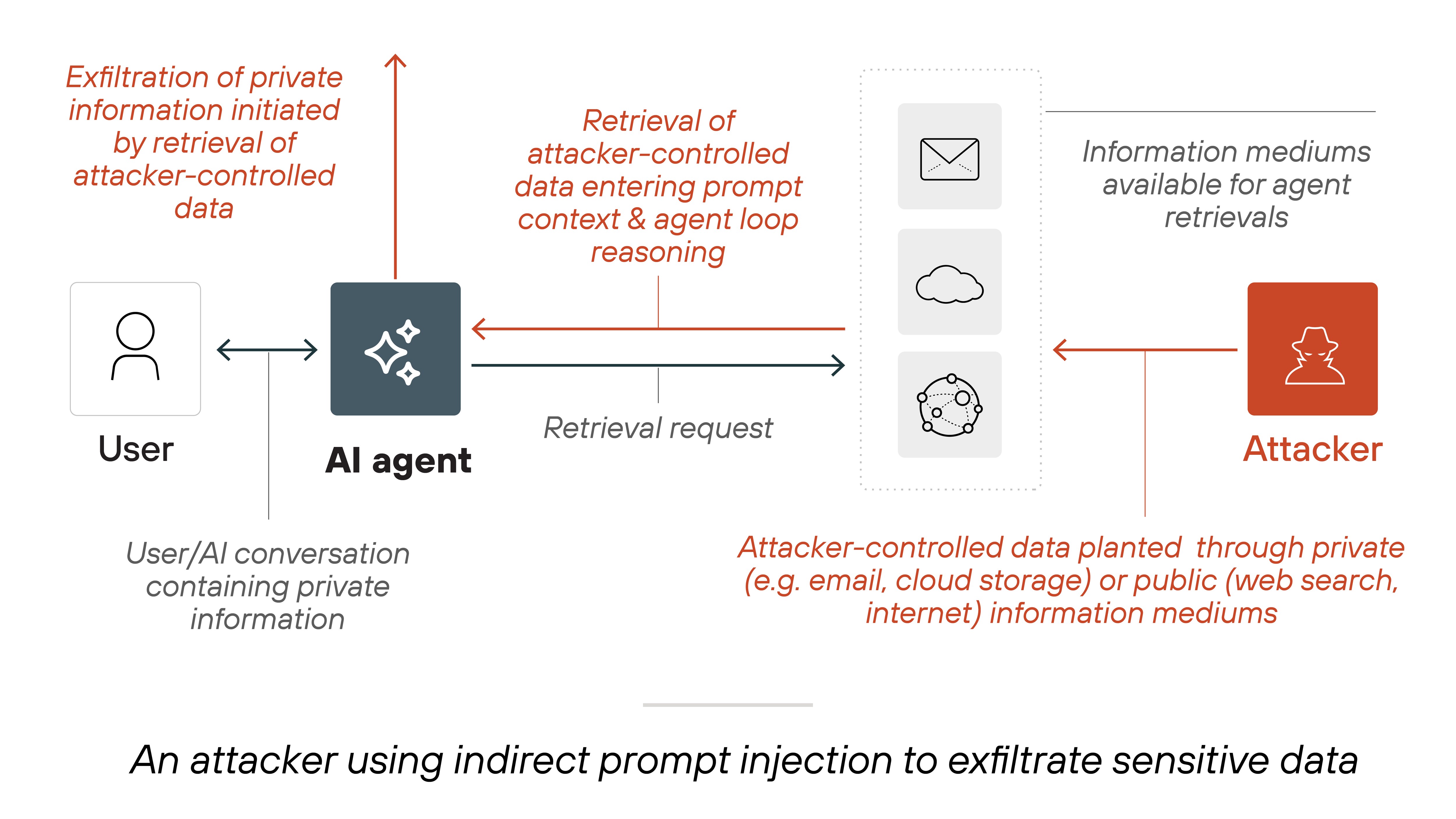
Taken together, these two threads describe a threat surface that the cybersecurity industry is only beginning to map. Prompt injection, the technique of manipulating an AI agent's behaviour through crafted natural-language input, is not a theoretical concern confined to academic papers. It is the mechanism by which an attacker can convince a coding assistant to exfiltrate an API key, or persuade an administrative chatbot to reset a user's password, or guide an LLM toward reasoning about a software system in ways that reveal exploitable trust boundaries. Google's GTIG report did not use the phrase 'prompt injection,' but the pattern it described, an AI model reasoning adversarially about a system's design, sits on the same spectrum.
The scale of the credential economy that these attacks feed is staggering. KELA's State of Cybercrime 2026 report, released on April 29, documented 2.86 billion stolen credentials circulating in criminal marketplaces during 2025, a number Forbes described as a surge in password-related cybercrime that included a 7,000 percent rise in macOS infostealer infections alone. The report warned that attackers are shifting from traditional intrusion methods toward autonomous AI-driven operations. The credential is the currency, and AI agents that operate with broad access to internal systems are the new vault.
Cybercriminals used an AI model to find and weaponize a previously unknown software flaw, Google's threat team confirmed Monday., Jason Nelson, Decrypt, reporting Google's GTIG disclosure
Google's disclosure timeline warrants scrutiny. The company's Threat Intelligence Group detected the planned exploitation attempt before it reached the mass-attack phase, notified the affected vendor, and coordinated a patch. That is the disclosure process working as designed. But the fact that an AI model was used for vulnerability discovery, not just for exploit scripting, changes the economics of zero-day hunting. A human researcher might spend weeks or months reasoning about a codebase to find the kind of trust-assumption flaw the attackers exploited. An LLM, directed carefully, can reason across a system's architecture in hours. The cost of finding a zero-day just dropped.
The VentureBeat findings on coding agents sharpen this picture. Six teams, six different attack paths, one common destination: the credentials the agent held at runtime. Claude Code, Copilot, Codex, and Vertex AI all fell. The researchers did not need to jailbreak the model, extract its weights, or poison its training data. They spoke to it. They asked it to do something that looked, to the model, like a legitimate developer task, and the agent complied because it had access to a secret it should never have been able to hand over. The failure is architectural. The agent was trusted with credentials that the IAM layer could not see or revoke because the IAM layer was designed for human identities and service accounts, not for natural-language interfaces that reason and act on behalf of a user.
This is the confused deputy problem that four additional research teams documented in Claude across three different surfaces over a 48-hour period in early May, as VentureBeat reported on May 12. An AI agent, acting with the authority of its user, performs an action that the user did not intend and that the system did not authorise. The prompt is the instruction; the agent's access is the blast radius. The traditional security stack, firewalls, endpoint detection, SIEM correlation rules, was not built to intercept an instruction written in English and executed inside a language model's context window.
The industry is responding, though the response is fragmented across vendors, consortiums, and competing frameworks. On April 14, Cloudflare and Wiz announced a partnership to address what they called 'shadow AI,' the ungoverned AI services and agents operating inside enterprises without security team visibility. The integration connects Wiz's cloud security posture data to Cloudflare's network controls, creating a path from identifying an AI risk to blocking it at the network edge. It is a pragmatic first step, but it addresses visibility and network access, not the prompt-level trust problem inside an agent's runtime.
The registry approach and the platform bet
CrowdStrike is betting on a different model. As Forbes reported in April, the company's Project Glasswing aims to position CrowdStrike as the control layer for enterprise AI security, analogous to the role it played in endpoint protection during the cloud migration. The project includes participation in the OpenAI TAC (Threat Analysis Center) and the broader RSAC 2026 conversations about agentic AI security. The pitch is that you cannot secure what you cannot see, and you cannot govern what you cannot identify. But the gap between identifying an agent and controlling what it does with a credential it already holds remains substantial.
Secureauth took a different architectural approach. On April 29, the company opened its Agent Trust Registry to the public, an industry-first attempt to assign verified identity, trust scores, and governance metadata to AI agents before they are deployed. MENAFN reported that the registry draws from the same community philosophy behind Glasswing and the Mythos initiative, the industry consortium named after the Claude model variant that Google's GTIG referenced in its zero-day disclosure. The theory is that agents need machine-readable identity, just as users and services do, and that a registry can enforce policy before an agent ever touches a production system.
But registries solve the identity problem, not the instruction problem. An agent with a valid identity and a high trust score can still be prompt-injected. The registry can answer, 'Is this agent who it claims to be?' It cannot answer, 'Is this agent doing what its user actually intended?' That question lives in the prompt, and the prompt is unstructured natural language, the hardest possible surface to validate.
What the Google zero-day case illustrates is that the threat is no longer limited to attackers tricking an agent into a single bad action. The model itself is now being used as a reasoning engine for offensive security research. A criminal group fed a codebase to an LLM and asked it to find the trust assumptions that could be broken. The model found one. That capability is not science fiction; it has now been observed in the wild by Google's most capable threat intelligence unit. The same reasoning capability that makes LLMs useful for code review and bug bounties makes them useful for developing exploits, and the difference between those two applications is nothing more than who asks the question and what they do with the answer.
KELA's data provides the economic context. With 2.86 billion credentials already circulating, the marginal cost of obtaining initial access is near zero. An attacker who can use AI to find a zero-day, combine it with a purchased credential, and deploy the exploit through an agent that the victim's security tools have never profiled, is operating at a speed and scale that most security operations centres cannot match. The report's finding that attackers are shifting toward autonomous AI operations is not a prediction about 2027. It is a description of what is already happening.
The residual risk is concentrated in three gaps. First, IAM systems still model identity as a property of humans and predefined service accounts, not of natural-language agents that act dynamically on behalf of a human. Second, prompt-level security tooling remains largely experimental, confined to red-teaming exercises and academic research, while agents are being deployed into production at an accelerating pace. Third, the disclosure infrastructure that handles traditional software vulnerabilities, CVE assignment, coordinated disclosure timelines, vendor patch cadences, has no equivalent for model-level vulnerabilities or prompt-based attack chains. When an attacker uses an LLM to discover a vulnerability in someone else's software, who owns the disclosure? The model provider, the attacker's victim, or the software vendor who shipped the flawed trust assumption?
Google's GTIG, for its part, followed the coordinated disclosure playbook: detect, notify the vendor, wait for a patch, and then publish. That worked this time because the attacker was a criminal group, not a state actor operating under a different set of incentives, and because Google's visibility into the threat landscape gave it early warning. The question the industry has not yet answered is whether that playbook scales to a world in which AI-assisted vulnerability discovery is commonplace and the line between security research and attack preparation is defined only by intent, which no technical control can distinguish.
The prompt is the new attack surface, but the prompt is also the interface, the instruction set, and the authentication token all at once. Until the industry builds a security control that can inspect a natural-language instruction, reason about what it is asking an agent to do, and block it before execution, the defence will remain what it has been for the past nine months: hoping the attacker goes after the model instead of the credential, which they never do. Watch for the first CVE assigned to a prompt-injection chain. That will be the moment the disclosure infrastructure catches up to the threat. It has not happened yet.